
Volume 191
Published on October 2025Volume title: Proceedings of CONF-MLA 2025 Symposium: Intelligent Systems and Automation: AI Models, IoT, and Robotic Algorithms
Accurate short-term temperature prediction is of great significance in fields such as agricultural production and disaster prevention and mitigation. This study aims to explore the performance differences among three models—Convolutional Neural Network (CNN), Transformer, and Random Forest (RF)—in short-term temperature prediction tasks, providing a reference for model selection and optimization in meteorological forecasting. Based on the Beijing PM2.5 dataset, the research constructs supervised learning samples through data preprocessing (using the temperature sequence of the past 24 hours as input to predict the temperature at the 25th hour) and trains and evaluates the three models under unified experimental configurations. The results show that all three models can achieve high-precision predictions. Among them, Random Forest performs the best , with significant advantages in error control, noise resistance, and high training efficiency. CNN follows and excels at capturing local short-term fluctuation features. Transformer , although capable of modeling long-range dependencies, performs slightly inferior with the current dataset. The study reveals that traditional machine learning models still have practical value in resource-constrained scenarios, while deep learning models can further improve accuracy when sufficient data is available. Model fusion and the introduction of multiple factors may be future optimization directions.



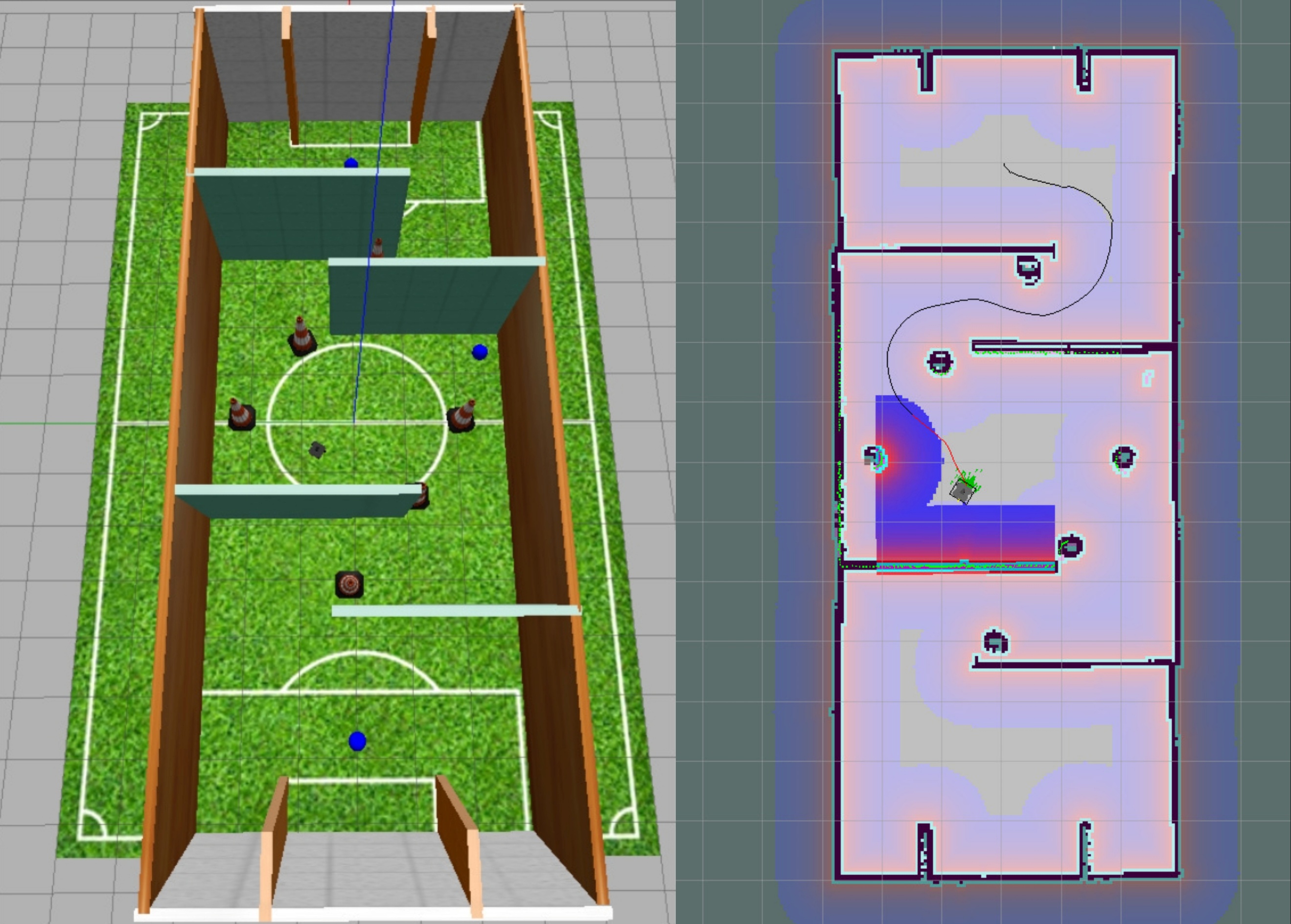
In modern robotic autonomous operations, navigation and dynamic interaction in unstructured scenarios are key to achieving efficient operations. However, current research on visual perception-based robotic systems lacks adaptability to unstructured scenarios and integration with engineering applications. This article reviews visual perception-driven intelligent navigation and dynamic interaction for robotics, analyzing the technical modules of visual SLAM and navigation collaboration, visual object recognition optimization, and multi-node autonomous interaction. The research found that the collaboration between visual SLAM and navigation has mostly been demonstrated in ideal environments, visual recognition algorithms are less adaptable to complex interference, and the engineering integration of "navigation-recognition-interaction" needs to be strengthened. This review aims to establish a solid theoretical foundation for designing robotic systems in low- and medium-complexity scenarios, advance visual perception technology from laboratory research to industrial application, and contribute to breakthroughs and developments in related fields.
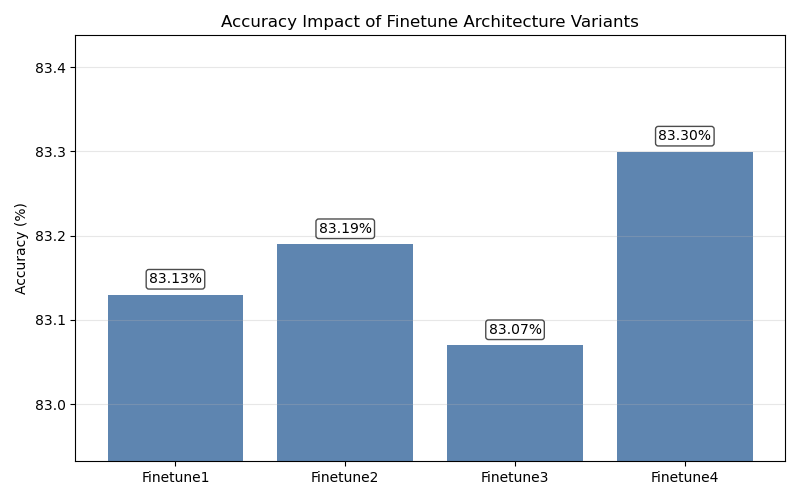
To address the challenges in fine-tuning Pre-trained Language Models (PLMs) like BERT, where performance is highly sensitive to architecture and hyperparameter choices, this study proposes and validates a systematic two-stage optimization process using the MRPC sentence pair classification task. Progressing from architecture exploration to parameter optimization, our experiments first reveal that a simplified single-layer linear classifier outperforms more complex structures for this task. Subsequently, large-scale hyperparameter tuning identifies batch size as the most critical parameter, while others like learning rate exhibit a distinct optimal range. By implementing this structured methodology, we significantly improved the model's validation accuracy. This work demonstrates that a methodical approach, combining fine-grained architecture adaptation with systematic parameter tuning, is crucial for realizing the full potential of pre-trained models.
Since the release of Practices for Governing Agentic AI Systems by OpenAI in 2023, the emerging paradigm of Agentic AI (Artificial Intelligence) has gradually attracted academic attention. Unlike traditional AI systems that rely on structured presets and extensive human intervention, Agentic AI refers to intelligent systems capable of understanding task objectives, adapting to complex environments, and autonomously completing tasks with minimal human oversight. Its advantages in adaptability, decision-making, and self-management make it particularly suited to dynamic and rapidly changing real-world scenarios. This paper first outlines the definition, core characteristics, and primary enabling technologies of Agentic AI, emphasizing that, to date, no deployed system in the gaming domain fully embodies all of its defining features. To explore potential pathways toward practical implementation, the paper analyzes several recent large-model-based agents—such as SIMA, and ChatRPG v2, that, while falling short of the full Agentic AI standard, exhibit partial alignment through capabilities such as autonomous instruction comprehension, long-term task execution, multi-environment adaptation, and low-intervention deployment. These systems can therefore be regarded as generative agents with Agentic characteristics, offering valuable insights for future research directions and technical architectures. Finally, the paper proposes using gaming environments as low-cost, low-risk, and highly controllable testbeds for validating key capabilities, accumulating deployment experience, and accelerating the transition of Agentic AI into real-world applications, thereby advancing game AI from scripted logic toward higher levels of autonomous intelligence.
Reinforcement learning (RL), as a core technology of artificial intelligence, has shown strong potential in the fields of robotics, games and autonomous driving. However, the "black box" nature of deep RL models leads to a lack of transparency in the decision-making process, making it difficult for users to understand and trust the agent behavior of RL models, and the uninterpretability of decisions may cause serious consequences in sensitive fields such as healthcare and finance. At the same time, because traditional RL pursues maximum reward and result models often ignore fairness, leading to policy bias, which affects the group's rights. So this article will summarize from the perspective of two key transparency and fairness of RL as summarized in the paper: one is based on the interpretability of the decision-making method, using the causal analysis and partial interpretation and visualization tools to make decisions transparent; Second, the decision-making method based on the constraint conditions, through multi-objective optimization and gradually constraints ensure the decision unfair. This review covers the methodologies, experimental results and limitations of representative literature in recent years. The significance of this paper is to systematically integrate these methods, reveal the interaction challenges of transparency and fairness, promote the development of more reliable RL systems, and look forward to future directions to help promote the ethical deployment and sustainable innovation of RL in social applications.
The exponential growth of user-generated content on social media platforms (e.g., Twitter, Weibo, Facebook) has created massive datasets rich in public sentiment. While sentiment analysis proves vital for understanding social trends, brand perception, and political developments, traditional methods struggle to handle the informal nature, noise, and context-dependent characteristics of social media language. This necessitates advanced computational technologies to extract meaningful insights. This paper summarizes the application of Python in social media text sentiment analysis, covering various methods supported by its NLP library (NLTK, TextBlob), machine learning/deep learning framework (TensorFlow, PyTorch), and discusses cross-platform comparative analysis and specific domain adaptation. The results indicate that Python-based models achieve high levels of accuracy. For example, the RoBERTa-BiLSTM-MHA model achieved an accuracy of 93.44%, and these models outperform conventional tools by 6–12% in terms of F1 scores. Key findings reveal cultural and platform-based disparities in sentiment expression. Specifically, Chinese social media platforms like Weibo emphasize economic sentiment, while Western platforms such as Twitter focus more on technical and ethical implications. The integration of sentiment dictionaries and multimodal data, including emojis, further enhances the robustness of these sentiment analysis models. Overall, this review underscores Python’s versatility in enabling scalable and real-time sentiment analysis, which in turn drives innovations in NLP research and practical applications.
Typhoons rank among the most destructive natural disasters globally, inflicting substantial casualties and enormous economic losses across the world each year. Accurate typhoon detection, tracking, and intensity estimation are crucial for disaster warning and risk management. Traditional typhoon monitoring methods primarily rely on numerical weather prediction models and expert judgment, which suffer from limited accuracy and insufficient timeliness. In recent years, the rapid development of deep learning technologies has brought new opportunities to typhoon research, particularly demonstrating significant advantages in multi-modal remote sensing data fusion and automated feature extraction. This paper systematically reviews the current state of typhoon detection, tracking, and intensity estimation technologies based on deep learning, analyzes the application of multi-modal remote sensing data in typhoon monitoring, discusses current technical challenges, and prospects future development trends. Research indicates that deep learning methods show superior performance in automated typhoon feature recognition, temporal sequence modeling, and multi-source data fusion, providing new technical pathways for improving typhoon forecasting accuracy and operational efficiency.
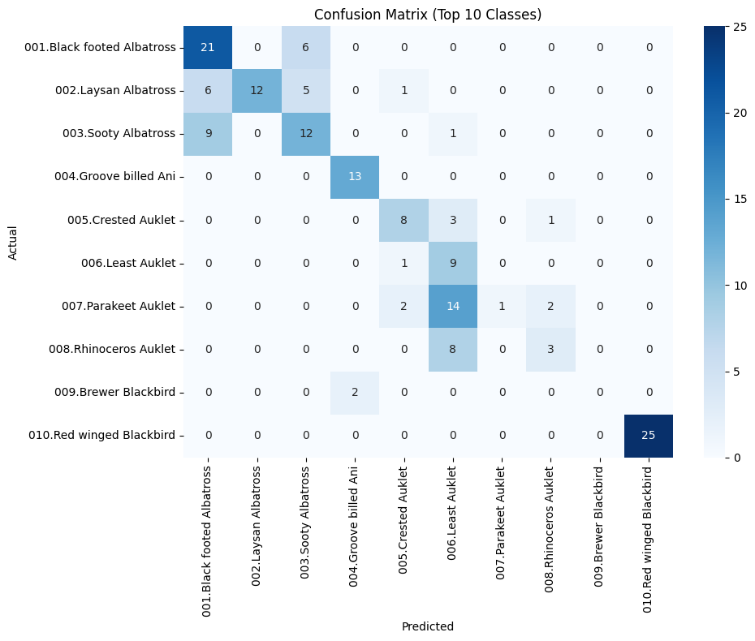
Fine-grained image classification is challenging because categories are often separated by only minor visual cues, requiring models to capture very fine details for accurate discrimination. The latest advances in vision-language models, such as CLIP and LiT, have demonstrated strong zero-shot performance on general image recognition tasks, but their effectiveness in fine-grained domains remains underexplored. In this study, we conduct a comparative evaluation of CLIP, LiT, and the vision-only Swin Transformer on the CUB-200-2011 bird dataset. For zero-shot classification, we assess CLIP and LiT using a consistent prompt template, while for fine-tuning, we train both CLIP and Swin end-to-end using the AdamW optimizer. Results show that LiT outperforms CLIP in zero-shot settings (63.96% vs. 51.55% Top-1 accuracy), while Swin achieves the highest performance after fine-tuning (83.47% Top-1 accuracy). These findings highlight a trade-off between generalization and fine-grained specialization, and suggest that future work should explore lightweight adaptation techniques to bridge the performance gap without sacrificing zero-shot flexibility.
YOLOv8 offers high accuracy and real-time performance, making it suitable for UAV applications. However, challenges such as limited onboard computing power, varying target sizes, and complex environments persist. This review systematically explores recent advancements in optimising YOLOv8 for drone applications, while also studying and evaluating its performance under extreme conditions such as low light and occlusion. The results indicate that current optimisations primarily focus on three directions. First, improving small object detection accuracy through multi-scale feature fusion, attention mechanisms (such as hybrid attention modules), and data augmentation (such as adaptive anchor allocation). Second, achieving model lightweighting and edge deployment through backbone replacement (such as MobileNetV3), model quantisation, and embedded deployment optimisation. Additionally, robustness in complex environments is improved through techniques such as image preprocessing (e.g., CLAHE, gamma correction), adversarial training, and multimodal fusion..This work aims to guide future studies toward automated optimization, edge-cloud integration, and multi-task learning for intelligent UAV vision systems.