
Volume 132
Published on October 2025Volume title: Proceedings of CONF-APMM 2025 Symposium: Simulation and Theory of Differential-Integral Equation in Applied Physics
Traffic flow prediction plays an important role in intelligent transportation systems, supporting efficient traffic management and scientific decision-making. With the rapid advancement of deep learning, various advanced models have sprung up, aiming to capture the nonlinear, high-dimensional and dynamic evolution of traffic data. This paper systematically reviews three representative methods: autoencoder-based models, recurrent neural networks (RNNs), and graph neural networks (GNNs). With its stack-optimized structure, Autoencoder has demonstrated its capability in feature extraction, noise reduction and efficient representation learning, thereby improving prediction robustness and computational efficiency. RNNs and their variants (including LSTM and GRU) excel at portraying the temporal dependence of traffic sequences, while hybrid models that incorporate external data or optimize algorithms further enhance accuracy and adaptability. In recent years, GNN methods have emerged to specialize in spatial dependencies caused by complex road network structures. By combining GCNs with temporal models and enhanced learning, these methods have achieved remarkable results in capturing spatio-temporal correlations and long-term predictions. Overall, the integrated evolution of AE, RNN and GNN models explains the leap-forward development from feature compression, temporal modeling to spatio-temporal integrated learning. Despite the significant advantages, challenges remain in multimodal data fusion, computing efficiency and real-time deployment, which points out a promising direction for future research.



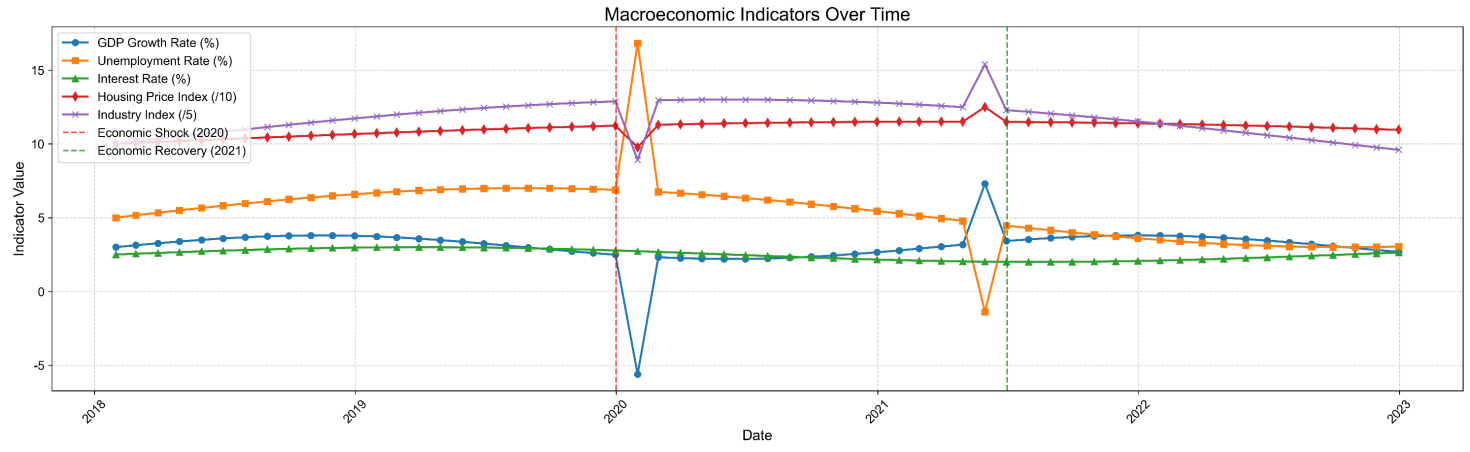
Traditional credit risk models, focusing primarily on borrower-specific features, often fail to capture the impact of macroeconomic fluctuations, leading to systemic misjudgment during downturns. This paper proposes enhancing loan prediction models by integrating an "economic sensor" – a module incorporating key macroeconomic indicators (GDP growth, unemployment rate, interest rate, Housing Price Index, Industry Index) processed via a temporal sliding window mechanism. We develop an economic shock simulator for stress testing. Using a synthetically collected 5-year data set of loan applications and macroeconomic conditions, we train Random Forest models. Results show the enhanced model (individual and macro features) outperforms the baseline (individual features only), with accuracy increasing from 83.13% to 85.21% and AUC from 0.8993 to 0.9217. The model demonstrates heightened sensitivity to economic shocks, evidenced by a rightward shift in the predicted default probability distribution and an increase in the mean predicted default rate from 21.5% to 31.8% post a simulated 20% housing price crash. Crucially, it provides early warnings, identifying 2,873 clients (75% SMEs) with significantly increased risk 3-6 months post-shock. This approach enables more robust, economically-aware credit risk assessment.
Disruptions such as pandemics and energy shocks weaken the reliability of carbon-emission models. Physics-guided machine learning (PIML) offers a practical response. This review explains how PIML improves robustness when temporal continuity breaks and system structure shifts. It covers four methods: physics-informed neural networks; hybrid or embedded designs that use CTM outputs and differentiable operators; post-processing that enforces physical feasibility; and structured or graph-based models that encode conservation and transport while keeping interpretability. Evidence shows these methods are more robust with sparse data and under distribution shifts. Yet challenges remain: balancing loss terms, dealing with complex boundaries, keeping physical inputs up to date, and the high cost of multi-scale problems. On the application side, the review focuses on pandemic-driven demand contraction, energy-supply shocks with fuel switching, and policy-induced structural change. These scenarios guide evaluation and benchmarks and help improve reliability under disruptions. On the practice side, recommended tactics include reliability-weighted fusion, adaptive coupling, explicit uncertainty handling, and dynamic graphs.
Customer churn is a critical issue in the telecommunications industry. With digital transformation and the growth of customer data, churn prediction models have become an indispensable tool for telecom operators. This paper comprehensively reviews recent research on customer churn prediction in the telecommunications industry. Common datasets are examined, including public benchmarks such as IBM Telco and Cell2Cell, as well as large-scale proprietary datasets. Four categories of approaches are discussed: traditional machine learning, ensemble and hybrid methods, deep learning, and explainable artificial intelligence (XAI). Ensemble models and deep learning hybrid methods maintain excellent performance, in some cases reporting accuracies exceeding 90%. However, deployments still face common challenges such as class imbalance, overfitting, and limited interpretability. Furthermore, research gaps are identified, including the need for multimodal data integration, real-time prediction, improved interpretability, and privacy-aware methods. By summarizing state-of-the-art techniques and remaining challenges, this review provides guidance for future research and practical implementation of customer churn prediction in the telecommunications sector.
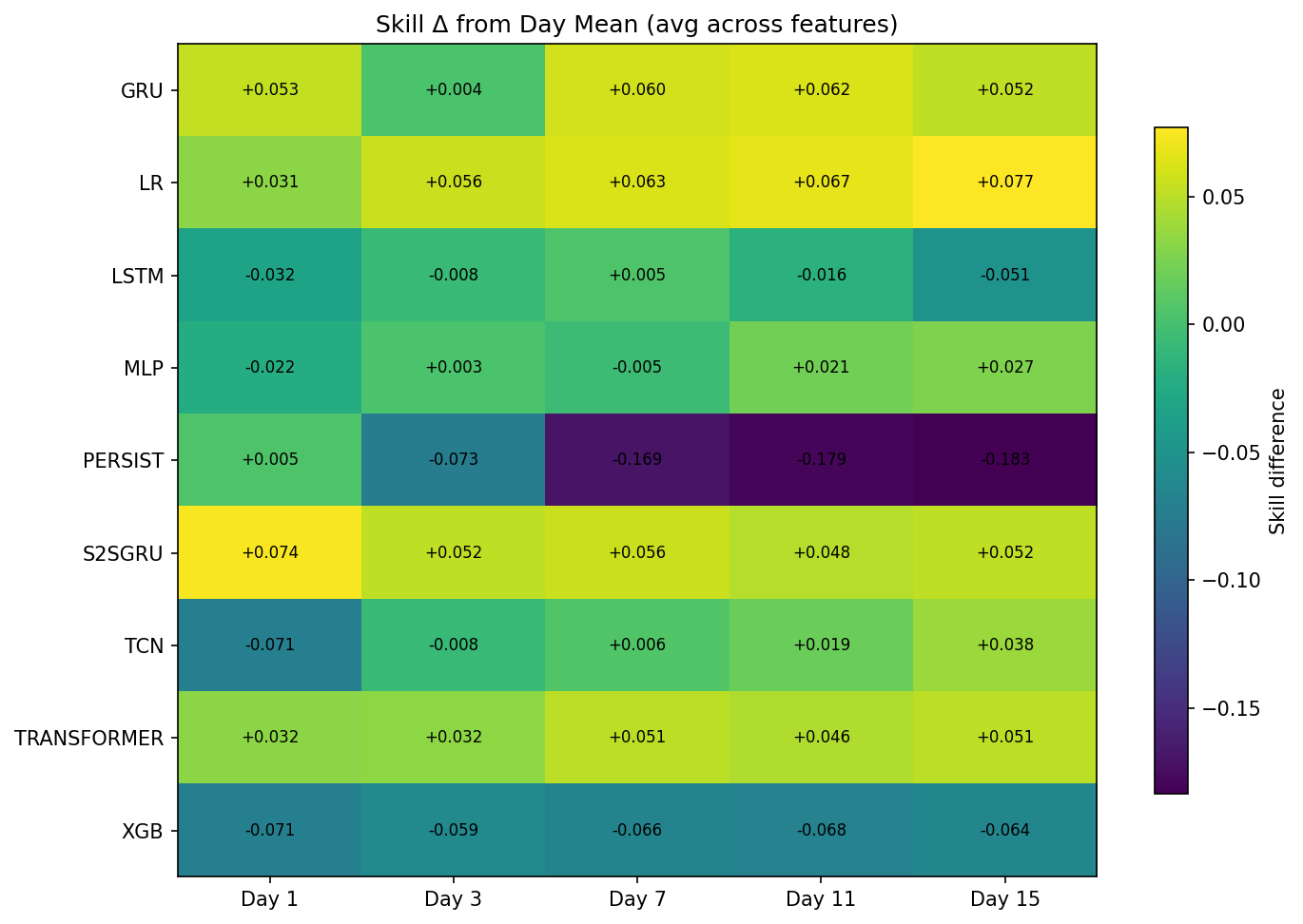
This study focuses on a comparative study of machine learning methods on offline weather forecasting with short lookback windows and limited computational resources. Using 90 days of single-station GSOD inputs, models predict 15-day horizons for temperature, precipitation, wind speed, and visibility. Evaluation with Nash–Sutcliffe efficiency, RMSE, and inference time shows that Linear Regression is a surprisingly strong and stable baseline, excelling in wind speed and remaining competitive across variables. Transformer models perform best for temperature by capturing long-range dependencies, while sequence-to-sequence GRUs outperform others on precipitation and visibility. In contrast, XGBoost and persistence baselines consistently underperform in this constrained setup. In inference time, LR outperform all other methods due to its simplicity. The results indicate that simple linear models can excel in this scenario compare to deep learning approaches, while specialized neural architectures provide targeted gains, suggesting a combination of models could be the most effective for practical low-resource forecasting.
Alcohol consumption among secondary school students carries significant risks to academic performance and long-term health. While prior studies have already established static correlations between drinking behaviors and grades, the temporal dynamics of behavioral transitions remain unexplored. This study employs a Markov chain model to analyze students’ drinking patterns across different academic periods (G1–G3), using a dataset of from Kaggle and the UCI Machine Learning Repository. This data contains students’ Portuguese and math grades, as well as their weekdays and weekends’ alcohol consumption. This study also quantifies transitions between drinking states (low/moderate/high), examining gender and weekday-weekend disparities, and assessing academic impacts through ANOVA and linear regression. The key findings reveal that, Male students exhibit persistent high-risk drinking states on weekends (male=3 vs. females=2), with a 70% retention probability in Markov transitions. Each 1-level increase in weekend drinking correlates with a 0.35-point grade decline (p-value < 0.001). Weekday drinking is uniformly low (level 1) across all students, suggesting academic routines suppress consumption.
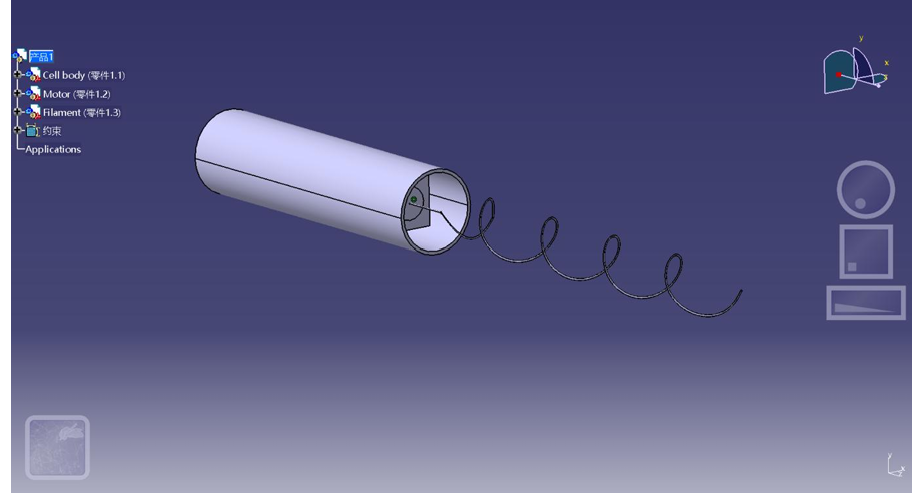
This study presents a bioinspired approach to modeling, scaling, and fabricating a helical flagellated swimmer, mimicking the locomotion of bacteria in low Reynolds number environments. The project integrates theoretical analysis using Buckingham Pi theorem, MATLAB simulations, and physical prototyping via 3D printing. A scaled macroscopic swimmer was designed with a target Reynolds number below 0.1 and tested in both water and detergent-based viscous media. Experimental results were compared with theoretical predictions, and velocity-angular velocity relations were derived. This work demonstrates a hands-on methodology bridging microscale fluid dynamics with accessible macroscopic experiments, serving as both a research and teaching model.
This survey reviews the fundamental principles and major approaches used in modern forecasting, with a focus on numerical weather prediction (NWP) and deep learning. NWP remains the cornerstone of operational forecasting, utilizing mathematical equations of atmospheric dynamics to produce high-resolution predictions. The computational demands and strengths of physics-based methods are exemplified by representative models such as the Global Seasonal Forecast System (GloSea5) and the Weather Research and Forecasting (WRF) system. However, deep learning techniques like as convolutional architectures and distribution-based neural networks each have advantages that make them helpful for examining huge meteorological datasets with nonlinear correlations. Validation, uncertainty quantification, model interpretability, and accurate forecasting of extreme weather events remain challenges despite advancements. It is anticipated that future advancements in high-performance computing, multi-source data assimilation, and hybrid methodologies that integrate machine learning and physical modeling will increase the utility and dependability of predictions. This study summarizes recent advancements, points out unresolved issues, and suggests exciting avenues for further weather forecasting research.
The group theory, as one of the cornerstones of the modern algebra, has a profound historical trajectory that reflects the evolution of the mathematical thought. This comprehensive paper analyses the historical development of the group theory and provides an overview of the interconnectedness of the several key theorems in the group theory: The Lagrange’s Theorem, the Fermat’s Little Theorem and the Euler’s Theorem. This paper begins by establishing the modern group-theoretical framework within the Lagrange’s Theorem on the link between the order of groups and that of its subgroups. Then, an extension onto other related theorems are provided. In all, this paper is highly interlinking among the ideas in group theory. Ultimately, this study not only demonstrates the beauty of mathematical interconnections but also highlights their continuing relevance for the modern applications, showing how the classical results remain relevant to guide contemporary explorations in algebra, number theory, and related disciplines.
In the context of strengthening youth football training nationwide, promoting open and transparent selection of national football players, fostering a healthy football competition environment, advancing the modernization of coach education, improving the construction of the national football team, and comprehensively improving the level of national football, the factors influencing the outcome of football matches have been studied. This study provides scientific data analysis for team training, prompting coaches and players to further improve their personal and team tactical strategies, increase the team's winning rate, and analyze the factors that affect the outcome of football matches. Using key match data from the English Premier League in the DCD app multiple linear regression analysis was performed via SPSS to identify the 12 most critical factors affecting match results. Based on this, practical suggestions were proposed for teams to improve their winning probability from micro to macro levels, including players themselves, coaches, and the General Administration of Sport of China.