


1. Introduction
Education gives knowledge and good behavior. It improves one's ability to think, work, and act smartly. Children with learning disabilities might not learn as fast as normal children of the same age. They have difficulty with speaking, reading, writing, doing calculations, organizing things, and so on [1]. The specific learning disorders are classified into dyslexia, dysgraphia, and dyscalculia. Individuals with this problem may be unable to participate fully and competently in academic an activity, which leads to poor academic achievement. Even though the understanding of learning disabilities has evolved in recent years, diagnosing and assessing the severity of the disorder remains difficult. Teachers are important in evaluating children and advising parents to take their children to the doctor. A medical practitioner may have difficulty in diagnosing learning disability problems because they differ from one child to another.
Machine learning and deep learning methods are used to detect dyslexia. Machine learning learns from examples and progressively improves prediction accuracy and decision-making with experience over time. Existing machine learning techniques used for predicting learning disabilities are SVM [2][3], Logistic Regression[4][5], Naive Bayes, K-NN[6], Random Forest, and decision tree[7]. The goal of the review paper is to examine current advances in dyslexia identification and future research opportunities using machine learning and deep learning methodologies.
2. Literature Review
Psychologists perform standardized tests like reading and writing, memory tasks, and phonological awareness in the conventional identification method of dyslexia. Test scores are evaluated, and the scores help to identify whether the person is affected by dyslexia or not. Performances are evaluated based on scores. Poor-scoring children are identified as being dyslexic. The conventional method necessitates the presence of psychologists. These methods require more time and are expensive.
Machine learning is becoming increasingly popular for medical diagnosis and decision-making in the medical field. Data collection is the first and most important step in machine learning. The machine learning steps are depicted in Fig. 1. The quality and quantity of data collection determine the output efficiency. The authors used different tests to collect data. specially designed tests, checklists, questionnaires, online games, reading tests for eye tracking, MRI scans, EEG signals, images, and video, and web-based independent game tests for auditory and visual checking. Some tests require materials like customized tools and cameras, eye trackers, MRI scanners, EEG headsets, and corneal reflection systems.
|
Figure 1. DNA Schematic. |
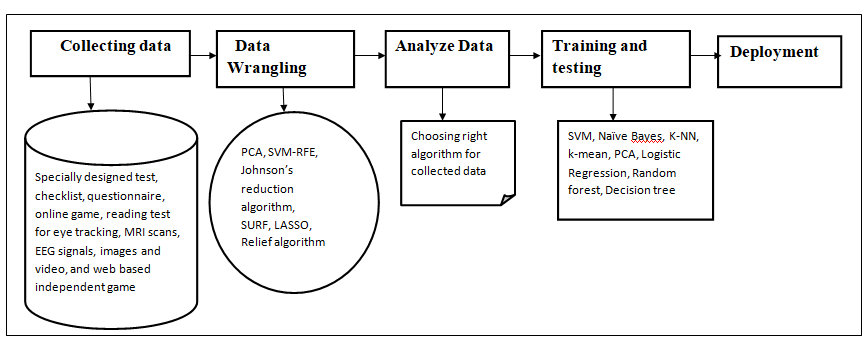
Machine learning algorithms are used to identify dyslexia. The researchers used various methods such as supervised, unsupervised, and ensemble approaches, and the convolutional neural network to detect dyslexia is described below. Table 1. to Table 3. shows the comparison of different algorithms used by researchers for detecting and improving the accuracy of dyslexia.
Table 1. Comparison of algorithms and accuracy score for the dataset collected through checklist.
Year, Author Name | Number of attributes | Test type | Data set | Techniques | Machine Learning Algorithm | Accuracy score |
[7], 2010, Julie M.David & Kannan Balakrishnan | 16 | Checklist | 125 real data sets | Decision Trees and Clustering | J48 Algorithm with K-mean clustering | 77.60% |
[8], 2010, Julie M.David & Kannan Balakrishnan | 16 | Checklist | 513 real data sets | Rough Sets | Naïve Bayes algorithm with Johnson’s reduction algorithm | 93.37% |
[9], 2010, Julie M.David & Kannan Balakrishnan | 16 | Checklist | 1100 real data sets | SVM | Sequential minimal optimization algorithm(SMO) in SVM | 97.86% |
[10], 2011, Julie M.David & Kannan Balakrishnan | 16 | Checklist | 513 real data sets | Comparison of Rough set with SVM | Naïve Bayes batch classifier with Johnson’s reduction algorithm | |
[11], 2013, Julie M. David, Kannan Balakrishnan | 16 | Checklist | 1020 real data set | Comparison of existing classifier and modified classifier with data preprocessing | Existing classifiers- ANN, J48, SVM, Naive Bayes. Modified Classifier- New ANFIS, New ANN, New Fuzzy | New ANN-99.03%, New Fuzzy -99.42%, New ANFIS-100% |
Learning difficulties are predicted using different rules drawn from the decision tree of the J48 algorithm. K-mean clustering identifies the various indications and symptoms found in a child with LD [7]. Attributes in rough sets are reduced and classified using Johnson's reduction algorithm and the Naive Bayes algorithm [8]. The author compares decision trees with rough set theory for detecting LD. It is found that the rough set performs better in terms of accuracy and categorization. SVM [9] is performed using the sequential minimal optimization technique, and decision trees are constructed using the J48 algorithm. The Naive Bayes Batch classifier [10] is used for rough set classification, and the results are compared to those from the SMO algorithm in the SVM study. The resulting SVM is very complex compared to the rough set method. The new ANFIS method [11] achieves the highest accuracy and a comparison is depicted in Fig.2
|
Figure 2. Performance of ML classifier for checklist dataset. |
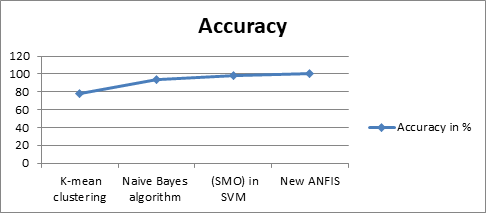
Table 2. Comparison of algorithms and accuracy score for the dataset collected through the Questionnaire gamet.
Year, Author Name | Number of attributes | Test type | Dataset | Techniques | Machine Learning Algorithm | Accuracy score |
[12], 2016, K.Ambili & P.Afsar | 16 | Questionnaire | 1124 instances | Artificial Neural Network | Accuracy, Learning Time, Error Rate | |
[13], 2016, K.Ambili & P.Afsar | 16 | Questionnaire | 1124 instances | Naive Bayes Algorithm and ANN | fusion of Naive Bayes and Neural network classifier | Accuracy, Learning Time, Error Rate |
The Naive Bayes algorithm outperforms the back propagation neural network in terms of accuracy. Both algorithm's outputs are combined and assigned random weights. It identified the combination that produces the highest level of accuracy. The Naive Bayes-Neural Network Fusion Technique performs better than each algorithm used alone [13].
Table 3. Comparison of algorithms and accuracy score for the dataset collected through the online-based game.
Year, Author Name | Number of attributes | Test type | Languages | Techniques | Machine Learning Algorithm | Accuracy score |
[14], 2016, Rello L and Williams K, et al | 6 | Online web-based Game | English and Spanish | Support Vector Machine | 85.85% | |
[15], 2020, Rello L, Baeza-Yates R et al | 196 | online gamified test | Spanish | Random Forests | Standard information the gain in decision trees, 10-fold cross-validation. | 76.80% |
[16], 2022, Shahriar Kaisar & Abdullahi Chowdhury | 196 | online gamified test | Spanish | Oversampling technique and Ensemble classifier | AdaBoost, Gradient Boost and XGBoost | 88.3%, 89.6%, and 90%. |
[17], 2020, Rauschenberger M & Baeza-Yates et al | ALL-33 Features,ES-41 Features, DE-38Features | web based game | German-DE, Spain-ES, ALL language | Random Forests and Extra Trees | Random Forest (RF), Extra Trees (ETC), Gradient Boosting (GB) | RF-74%German, ETC-69%spanish,GB-61% |
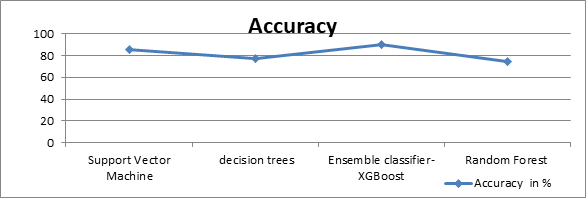
A Wilcoxon Signed-Rank test evaluates the variation between groups for nonparametric data. The SVM model detects dyslexia based on the data collected through web-based games [14]. Random forest [15] was applied for the online gamified test, which produced the highest accuracy compared to the web-based game test [17] using random forest. Imbalanced data is obtained during pre-screening tests. The author suggests using oversampling and ensemble methods for identifying dyslexia. Adaptive boosting, gradient boosting, and extreme gradient boosting were used as ensemble models. The ensemble technique ADASYN with XGB achieved an accuracy of 90% [16] compared to other algorithms in [14], [15], and [17] for the data collected through an online game [18][19][20]. The comparison is depicted in Fig. 3.
|
Figure 3. Performance of ML classifier for Online Gamified dataset. |
3. Conclusion
The authors used various techniques for detecting dyslexia. The performances of various methods in ML are compared for further improvement in the future. The ensemble method achieved 90% accuracy for data collected through an online game. Accuracy needs to be improved for the data collected through online games. Online gamified data collections are language-independent. Online gamified data collection does not require any customized tool, is less expensive, and can reach all users. The investigation aids us in providing a complete examination of each model, including methods, algorithms, datasets used, and various performance measures such as accuracy, specificity, sensitivity, etc.
A novel proposed methodology is to be adopted to increase the performance of the ML approaches. The design of interactive multimedia and machine learning-based mobile and computer-aided intelligent diagnostic and therapeutic applications shall be developed to help special educators in diagnosing, training, assessing, and monitoring those children. Detecting dyslexia alone will not help children recover from dyslexia. The therapy game application will be developed to help the children recover from the disorder.