


1. Introduction
In the era of traditional commerce, consumers often grapple with the inefficiencies and inconveniences associated with offline shopping. However, the ascent of information technology has paved the way for the blossoming of online shopping platforms [1]. These digital marketplaces, bolstered by technological advancements, offer consumers a vast selection from a myriad of household goods. The evolution from brick-and-mortar stores to online platforms was not merely a technological transformation; it marked a significant shift in consumer behavior and expectations [2].
Such convenience, while advantageous, is double-edged. The absence of a tactile experience in the digital realm can make discerning the true characteristics of products challenging. This plethora of choices, coupled with a lack of physical interaction, can overwhelm, often culminating in potential dissatisfaction or decision paralysis. Concurrently, this digital shift poses a conundrum for merchants, who grapple with tailoring their product recommendations without the nuances of face-to-face communication.
Product recommendation systems have long centered on the most basic keyword matching and manual filtering. Essentially, these systems attempt to predict and display items that a user is likely to purchase based on their preferences. Companies can use user preferences to determine which products to launch in order to maximize benefits. [3]. At their core, these systems predict and showcase items a user might gravitate towards, informed by explicit preferences or past interactions. The data extracted from these preferences is invaluable, guiding companies in product launches and business strategies, all to maximize customer satisfaction and benefits [4].
Deep learning has gained attention in recent years for its outstanding performance in tasks such as image and speech recognition and natural language processing. The rise of such tools has allowed us to make huge strides in tackling more difficult tasks, and the ability of deep learning algorithms to autonomously recognize and sift through large datasets to infer their features has made a quantum leap in recommender systems and changed the way they perform today. Utilizing advanced deep learning techniques, they successfully integrated their methodologies into Flipkart, India's premier e-commerce company. By doing so, they were able to effectively power visual recommendations throughout a vast catalog of 50 million products. The implementation of these deep learning strategies not only enhanced the recommendation quality but also showcased significant improvements in user engagement and sales metrics. The deployment of their solution had a significant business impact in terms of conversion rates [5].
In the backdrop of this rapidly evolving landscape, our study proposes an avant-garde deep learning-centric methodology for product recommendations. Deep learning, with its sophisticated neural networks, promises precision by intuitively bridging a user's potential preferences with pertinent product attributes. This harmonization, grounded in user background and product characteristics, is geared to deliver hyper-personalized recommendations. The aspiration is clear: to resonate with the user's intrinsic desires, ensuring elevated satisfaction levels and subsequently, higher conversion rates.
As we traverse through this paper's fabric, we'll elucidate the datasets employed, their significance, and nuances. This will be complemented by an in-depth exposition on our model's architectural choices, underpinning philosophies, and the experimental parameters that steered our research. The paper will culminate with a summative conclusion, juxtaposing our findings with existing literature, offering both a reflection on the present and a glimpse into the future of e-commerce recommendation systems.
2. Datasets
In the digital domain, intricate datasets are frequently the linchpin for transformative business insights. One dataset that particularly stands out [6]. Specifically designed to augment product recommendations, this dataset was meticulously compiled from the e-commerce giant, ShopMax, encompassing a staggering 100,000 individual user purchase records. Foremost, Yelp datasets [7] comprehensively chronicle diverse attributes: user demographics, purchase history, browsing patterns, and even product review sentiments. Such granularity isn't merely for academic indulgence. The demographic details, for instance, present a multi-faceted view of the modern consumer. It's not just about age or location; it's about decoding underlying trends. By analyzing the data through detailed model design, we can uncover the connection between users and products, thereby effectively predicting customer purchase intentions or identifying potential consumer groups for products. These are the latent patterns this dataset is poised to unravel.
However, possessing an expansive dataset is only half the battle. The real challenge, and opportunity, lies in its application. Here's where our proprietary model enters the fray. Harnessing state-of-the-art machine learning algorithms and deep learning networks, our model endeavors to transform this raw data into actionable business strategies.
The objective and accurate performance calculation method is the key to evaluate the performance of personalized product recommendation model. The commonly used evaluation methods are precision, precision and recall rate. The calculation methods of precision, accuracy and recall rate are as follows:
\( Accuracy=\frac{TP + TN}{TP+TN+FP+FN}\ \ \ (1) \)
\( Precision= \frac{TP}{TP+FP}\ \ \ (2) \)
\( Recall= \frac{TP}{TP+FN}\ \ \ (3) \)
Where TP, FP, TN, and FN indicate True Positives, False Positives, True Negatives, and False Negatives, respectively. A product recommendation with a high precision value suggests that the model's predictions are more likely to be relevant, while a high recall value indicates that the model identifies most of the relevant predictions.
3. Method
3.1. Personalized product recommendation model
In this section, a Personalized Product Recommendation Model (PPRM) is designed. For user attribute U and product attribute B, the probability of product recommendation can be calculated by formula (4).
\( R(u,b)=PPRM(U,B,θ)\ \ \ (4) \)
Where \( θ \) represents the parameters of our deep learning model, optimized during training. PPRM is shown in Figure 1.
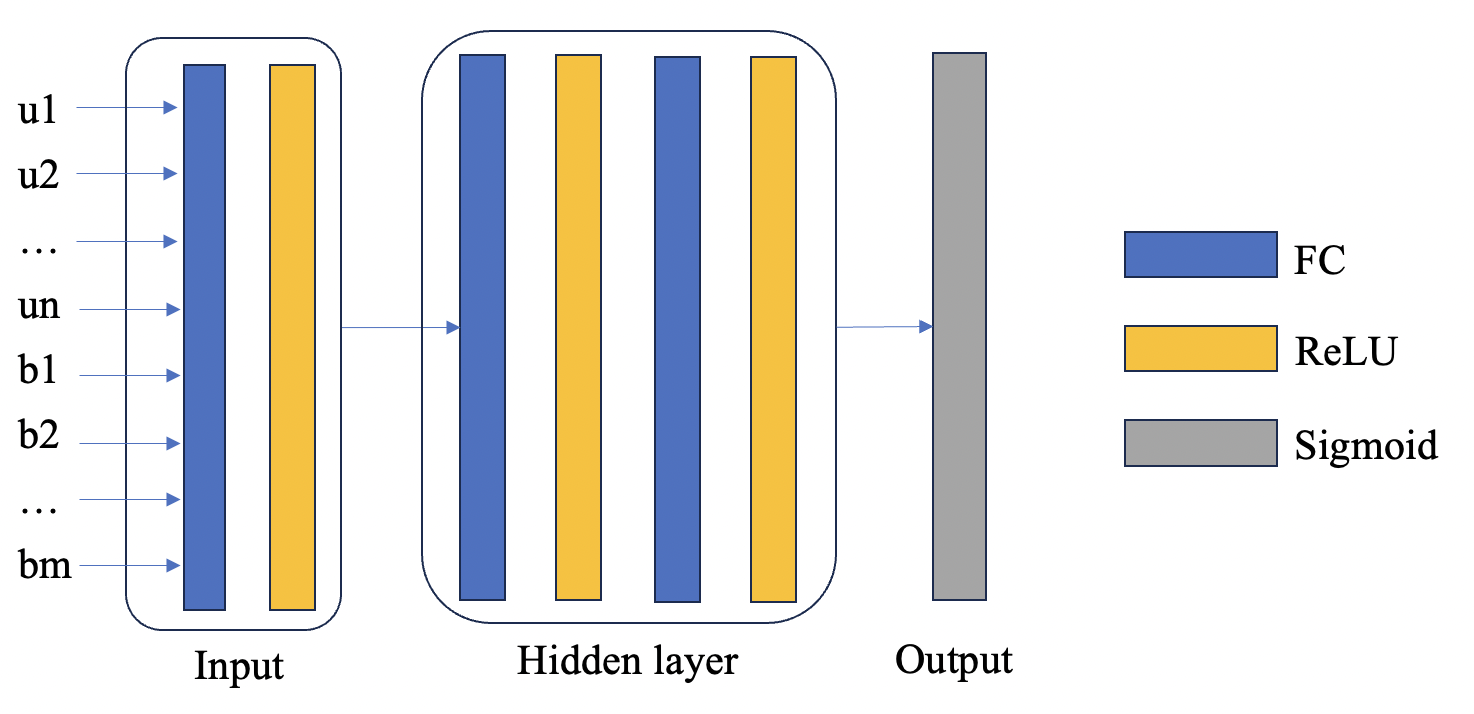
Figure 1. Personalized Product Recommendation Model (PPRM) consists of input layer, hidden layer and output layer. Where n indicates the number of user features and m indicates the number of product features.
The following describes the PPRM modules:
Input Layer: The starting point of PPRM, which converts the input data into a specific data length, which is input into the model for training.
Embedding Layer: The hidden layer consists of a fully connected network and an activation function, containing a large number of parameters that convert the features of the input into a result vector. ReLU, with its non-linear properties, ensures that the model can capture complex, non-linear relationships within the data, making the model's understanding deeper and more nuanced [8].
Output Layer: The output result of the model is a probability between 0 and 1, so it is necessary to normalize the output result range to the interval (0, 1), so the design output layer is composed of sigmoid.
Our present model is grounded in minimizing the variance between actual and predicted ratings, utilizing Mean Squared Error (MSE) as our loss function. Backpropagation ensures iterative refinement of our model parameters θ, with the Adam optimizer guiding this optimization process.
3.2. Experiment
Before we dive into the detailed model, it's essential to note the nature of our neural network's input. Our design primarily accepts matrices or vectors. This makes sense since our entire dataset consists of textual information. We leverage BERT [9] to convert this text into vectors, which then serve as the model's input. Additionally, the dataset's labels, quintessential for supervised learning, adopt a binary format. These labels, denoted as 0 or 1, play a crucial role in classification tasks, guiding the model during its training phase.
Our loss function, the absolute squared difference, was chosen to penalize significant deviations more heavily. It ensures that the model's predictions stay close to actual values, driving accuracy. Furthermore, the learning rate, a crucial determinant of how much the model updates with each batch of data, is set at 0.001. This modest value ensures a balance the model learns, but not too aggressively, preventing potential overshooting. Additionally, the batch size, set at 16, strikes a balance between computational efficiency and model learning speed. Smaller batches ensure more frequent updates, providing a more dynamic learning environment.
In conclusion, our deep learning model, designed with meticulous attention to data preprocessing, architecture, and parameters, stands poised to handle the multifaceted challenges of modern data.
3.3. Analysis
Through our model, we can precisely compute product recommendation probabilities based on customer and product information. This tailored approach optimizes user engagement, boosting the likelihood of purchases. Using advanced tools like Word2Vec [10] and BERT, our system delves deeper into the intricacies of product details to comprehend user preferences. Unlike traditional methods that rely on keyword matching, our methodology ensures recommendations are not just superficial but rooted in a profound understanding of user desires and product attributes. Furthermore, recognizing the sequence of user interactions over time has enhanced our model's efficacy. This innovation in e-commerce recommendation systems, blending traditional techniques with deep learning, sets the stage for future advancements in enhancing online shopping experiences.
4. Conclusion
In the contemporary research landscape, our study treads an innovative path. Leveraging Yelp's comprehensive dataset, our goal was to revolutionize product recommendations. Previous research primarily homed in on rudimentary interactions between users and businesses. However, our approach delved deeper, meticulously analyzing aspects such as the business environment and operational hours. This granularity not only differentiated our research but underscored its significance. Marrying the prowess of deep learning with this expansive dataset, we aspire to usher in novel insights, potentially reshaping the future of recommendation systems.
The essence of personalized product recommendations holds significant implications yet is riddled with challenges. After presenting an in-depth analysis of our dataset, we elucidated the model evaluation metrics employed. Capitalizing on specific methodologies, we proposed a model that showcased commendable performance in several domains. However, a caveat surfaces here; our method hinges heavily on extensive data. This reliance signals an area of potential improvement. Future research endeavors should pivot towards lightweight model architectures and explore techniques catering to scenarios with limited data. By embracing such a direction, we can potentially enhance model efficiency and democratize its applicability, aligning with diverse datasets and broader use cases.