


1. Introduction
Computer communication refers to the exchange of information and data between computers or computing devices. It involves the transmission, reception, and processing of data through various communication channels. With the rapid advancement of technology, computer communication has become an integral part of our daily lives, enabling seamless connectivity and facilitating efficient information exchange [1].
One of the key components of computer communication is networking. Networking allows multiple computers to connect and communicate with each other, forming a network infrastructure. This infrastructure can be local, such as a home or office network, or it can be global, such as the internet. Networking protocols, such as TCP/IP (Transmission Control Protocol/Internet Protocol), govern how data is transmitted and received over these networks, ensuring reliable and secure communication.
Computer communication encompasses various modes of communication, including wired and wireless [2]. Wired communication involves the use of physical cables or wires to transmit data between computers. This can be achieved through technologies like Ethernet, where data is transmitted in the form of electrical signals over copper or fiber-optic cables. On the other hand, wireless communication utilizes radio waves to transmit data without the need for physical connections. Wireless technologies like Wi-Fi and Bluetooth enable devices to communicate and share information over short distances.
The internet plays a crucial role in computer communication. It is a global network that interconnects millions of computers and networks worldwide. The internet enables communication on a massive scale, facilitating the exchange of information, services, and resources. Through web browsers, users can access websites, send and receive emails, participate in video conferences, and engage in various online activities.
In addition to networking and the internet, computer communication also involves protocols and standards that govern data transmission. These protocols specify the rules and procedures for establishing and maintaining communication between computers. Examples of such protocols include HTTP (Hypertext Transfer Protocol) for web browsing, SMTP (Simple Mail Transfer Protocol) for email communication, and FTP (File Transfer Protocol) for file transfer.
Security is a critical aspect of computer communication. As data travels across networks, it is vulnerable to eavesdropping, tampering, and unauthorized access. To ensure secure communication, encryption techniques, such as SSL (Secure Sockets Layer) and TLS (Transport Layer Security), are employed to encrypt data and protect it from being intercepted or modified by unauthorized parties. In conclusion, computer communication is a fundamental aspect of modern computing. It enables the seamless exchange of information between computers and networks, facilitating connectivity and enhancing productivity. With continuous advancements in technology, computer communication will continue to evolve, enabling us to communicate and collaborate more efficiently in the digital age.
Enhancing the quality of computer communication is a pivotal concern across various domains, such as networking and telecommunications. In recent times, there have been notable advancements in strategies to bolster the effectiveness of such communications. One prominent avenue of progress lies in the realm of wireless communication. The advent of 5G networks, coupled with ongoing research into the potential of 6G, promises to usher in a new era of communication. These networks are designed to provide substantially higher data transmission speeds, diminished latency, and augmented reliability, thus redefining the standards of wireless communication [3].
A second focal point in augmenting communication quality is Quality of Service (QoS) management. The implementation of QoS mechanisms within network infrastructures enables the prioritization of critical data traffic. This ensures that bandwidth-hungry applications such as video conferencing or real-time voice communication receive the necessary resources, guaranteeing an uninterrupted and high-quality user experience.
The concept of Edge Computing also warrants attention. By relocating computational resources closer to the data source, typically at the network edge, Edge Computing significantly mitigates latency issues. This is particularly advantageous for applications like Internet of Things (IoT) devices and autonomous systems, which demand real-time communication capabilities. Network Slicing, another noteworthy development, empowers the creation of multiple virtual networks on a shared physical infrastructure. This approach tailors network resources to the precise demands of specific applications or services, optimizing communication efficiency. Additionally, Software-Defined Networking (SDN) is emerging as a transformative technology. SDN facilitates dynamic network management, enabling rapid adaptation to shifting traffic patterns and the efficient routing of data.
In the domain of multimedia communication, the adoption of advanced codecs, such as AV1 and VP9, is on the rise. These codecs offer superior data compression and quality, consequently reducing bandwidth requirements for high-definition streaming. The incorporation of cutting-edge error correction techniques ensures the integrity of data transmission, even in situations characterized by noise or data loss.
Furthermore, block chain technology is increasingly being employed to enhance security and trustworthiness in communication, especially for sensitive data and financial transactions. Quantum communication techniques, such as Quantum Key Distribution (QKD), offer an unparalleled level of security for data transmission, catering to the needs of applications requiring ironclad data protection. Lastly, the utilization of artificial intelligence (AI) algorithms is gaining prominence. AI-driven solutions facilitate predictive network maintenance, real-time traffic optimization, and continuous monitoring, proactively identifying and mitigating issues that can adversely affect communication quality [4].
The Bit Error Rate (BER) is a metric in communication quality assessment. It quantifies the accuracy of data transmission by measuring the probability of erroneous bits in received data compared to the transmitted bits. A lower BER indicates higher communication quality, signifying fewer errors and greater data fidelity. This metric is indispensable in evaluating the robustness of communication systems, aiding in the optimization of protocols and technologies. BER analysis ensures that data is reliably transmitted, especially in noisy or challenging environments, crucial for maintaining communication quality in diverse applications, from wireless networks to optical fiber links, where precision and integrity are paramount [5].
In this paper, the utilization of the Viterbi algorithm in the refinement of word quality following the conversion from binary to natural language represents a methodological advancement in information processing. This algorithm, rooted in dynamic programming and widely acclaimed in error-correcting coding and speech recognition, plays a pivotal role in enhancing the precision and reliability of word reconstruction. By systematically decoding binary data streams, it minimizes errors and ambiguities, ensuring data fidelity. Moreover, its adaptability to probabilistic models and hidden Markov models endows it with versatility, making it an indispensable tool for elevating word quality. In academic endeavours focused on optimizing post-binary-to-word conversion, the Viterbi algorithm emerges as a fundamental instrument for information enhancement.
2. Theory
The Viterbi algorithm, named after its inventor Andrew Viterbi, is a dynamic programming algorithm used for various applications, notably in communication, error correction, and speech recognition. Its fundamental theory revolves around finding the most likely sequence of states in a hidden Markov model (HMM) by considering observed data, making it a powerful tool in decoding and sequence estimation problems.
At its core, the Viterbi algorithm operates on a trellis or lattice structure, where each node represents a state, and the edges between nodes correspond to state transitions. The algorithm seeks to find the most probable sequence of states that would explain the observed sequence of symbols or data. This sequence is often referred to as the "Viterbi path."
The Viterbi algorithm leverages dynamic programming to efficiently compute the probabilities associated with various state sequences. It accomplishes this through two main steps: the Forward Pass and the Backward Pass. In this phase, the algorithm calculates the likelihood of arriving at each state at a given time step by considering both the prior state probabilities and the transition probabilities. It also evaluates the likelihood of observing the current symbol in each state. These probabilities are stored in a table known as the "forward probabilities" or "alpha values."
The Backward Pass is the reverse process, where the algorithm calculates the likelihood of transitioning from each state to a final state while considering the future observations. These probabilities are stored in a table known as the "backward probabilities" or "beta values." Once both forward and backward probabilities are computed, the algorithm combines them to determine the most likely state sequence using the Viterbi path backtracking. The sequence with the highest overall probability corresponds to the optimal solution.
The Viterbi algorithm is widely used in various applications, including decoding error-correcting codes in digital communication, part-of-speech tagging in natural language processing, and voice recognition in speech processing [6]. Its efficiency and optimality make it a key tool in solving sequence estimation problems, where finding the most likely sequence of hidden states is paramount.
Part-of-Speech Tagging, often abbreviated as POS tagging or simply POS, is a fundamental task in natural language processing (NLP) that involves assigning grammatical categories or "tags" to each word in a given text based on its syntactic and semantic role within a sentence. This process plays a pivotal role in language understanding and is essential for various NLP applications.
The primary objective of POS tagging is to disambiguate the meaning of words in context, as many words can have multiple meanings depending on how they are used within a sentence. By tagging words with their respective parts of speech, such as nouns, verbs, adjectives, adverbs, pronouns, conjunctions, and more, POS tagging provides crucial information about the structure and grammatical relationships within sentences.
POS tagging algorithms typically rely on statistical models, rule-based approaches, or a combination of both. Statistical methods often employ machine learning techniques, like Hidden Markov Models (HMMs) or Conditional Random Fields (CRFs), to predict the most likely part of speech for each word based on contextual information from a large annotated corpus.
The applications of POS tagging are widespread and diverse. It forms the foundation for syntactic parsing, sentiment analysis, machine translation, and information retrieval. In search engines, it helps improve the accuracy of search queries by understanding the user's input and retrieving relevant results. In machine translation, POS tags aid in generating grammatically correct translations. In sentiment analysis, it assists in understanding the sentiment of individual words or phrases in a text, contributing to overall sentiment scoring.
In essence, POS tagging is a crucial building block in NLP, facilitating deeper language understanding and enabling a wide range of applications that rely on accurate grammatical and syntactic analysis of text data.
There is an input sentence [7]
x = x1, x2, …, xn (xi is the i’th word in the sentence)
and the tag line is
y = y1, y2, ..., yn (yi is the i’th tag in the sentence)
We can use HMMs to define
p(x1,x2,...,xn,y1,y2,...,yn)
Then the most likely tag sequence for x is
\( \underset{ y1 ...yn}{arg{ }max}{p(x1 ...xn,y1,y2,...,yn)} \)
where the arg max is taken over all sequences y1 . . . yn+1 such that yi belongs to S for i=1...n, and yn+1 =STOP
The format of Viterbi can be shown as [5]
\( p({x_{1}}…{x_{n}},{y_{1}}…{y_{n+1}})= \prod _{i=1}^{n+1}q({y_{i}}|{y_{i-2}},{y_{i-1}}) \)
\( \prod _{i=1}^{n}e({x_{i}}|{y_{i}}) \)
3. Simulations
After establishing the foundational elements of word possibilities and basic part-of-speech (POS) possibilities, we can leverage them for further applications. For instance, when presented with a sentence, we may seek to determine its corresponding POS tags.
Consider Table 1, a straightforward English sentence that also serves as an illustrative model. In this sentence, 'luna' represents a person's name, 'love' functions as the verb, and 'bee' is the noun. The sentence can be interpreted as describing an individual named Luna who likes a bee. Our objective is to employ the Viterbi Algorithm to ascertain the POS tags associated with each word in this sentence.
Table 1. Sample sentence we receive | |
PROCESSING SENTENCE: luna love bee |
Table 2 provides a comprehensive representation of prior word possibilities within a sentence. It delineates the various ways in which different words may appear within a sentence, shedding light on the likelihood of specific word roles. For instance, it quantifies the probability of 'luna' being used as a verb at 0.06 and establishes a substantial probability of 0.77 for verbs following nouns. This table serves as a pivotal resource for the Viterbi algorithm, enabling it to perform dynamic programming calculations efficiently. Moreover, it unveils essential insights into language performance, underlining the significance of word usage patterns and their impact on linguistic analysis.
Table 2. Possibility of POS | |
Sample | Distribution |
noun phi .80 | luna verb .06 |
verb phi .10 | love verb .03 |
fin noun .50 | bee verb .07 |
noun verb .77 | to inf .99 |
As we delve into the Viterbi algorithm's inner workings, we recognize its dynamic programming approach for part-of-speech (POS) tagging in sentences. The inherent sensitivity of words to their positions within a sentence becomes apparent, where a word's POS is intrinsically linked to the neighbouring words. For instance, the word 'bass' can be a noun, often associated with a following verb indicating a musical instrument, or it can be a noun related to a kind of fish, typically preceded by an adjective. Leveraging word position information greatly simplifies POS determination.
The Viterbi algorithm employs dynamic programming to calculate the probability of each word in various POS categories, selecting the highest probability as the final POS tag. The calculation for the word at position 'i' relies on the probability of the word at position 'i-1', extending from the first to the last word in the sentence. Additionally, it considers the possibility of a POS sequence, as represented in Table 2, to determine the likelihood of the next word being a particular POS category.
Table 3. final Possibility of POS | |
Possibility Distribution | |
P(luna=noun)=0.072000000 | |
P(luna=verb)=0.059000000 | |
P(love=noun)=0.000000354000 | |
P(love=verb)=0.001404000000 | |
P(bee=noun)=0.0000865743 | |
P(bee =verb)=0.00000003111 | |
P(bee =prep)=0.000000042100 |
Table 3 showcases the Viterbi Algorithm's POS tagging results for a sample sentence, where we assume four POS categories: noun, verb, infinitive, and preposition. It selects the highest probability for each word, thus determining its final POS tag.
Table 4. Back Points | |
Possibility Distribution | |
Backptr(love=noun)=verb | |
Backptr(love =verb)=noun | |
Backptr(love =inf)=verb | |
Backptr(bee=noun)=verb | |
Backptr(bee =verb)=noun | |
Backptr(bee =inf)=verb |
Table 4 illustrates the importance of the back pointers in the Viterbi Algorithm, aiding in the accurate tagging of POS positions. These back pointers significantly enhance the accuracy of POS tagging, especially for specific words in different contextual scenarios.
Table 5. Summary of Distribution | ||||||
Word | POS | Possibility | ||||
luna | noun | 0.0072 | ||||
love | verb | 0.0014 | ||||
bee | noun | 0.0086 | ||||
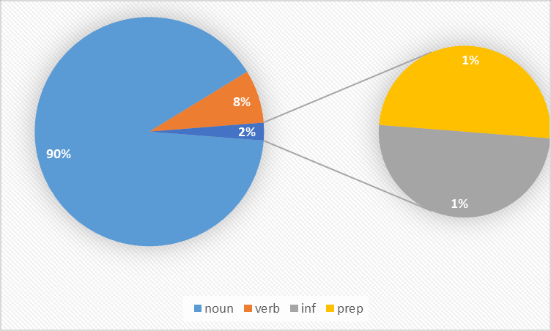
Figure 1. Word “luna” POS possibility performance
Table 5 presents the ultimate performance of the POS tagging process, showcasing the algorithm's success in tagging 'luna' as a noun, 'has' as a verb, and 'fish' as a noun, aligning with human judgment and ground truth. The probability values further indicate the algorithm's proficiency, with nouns being relatively easier to detect than verbs.
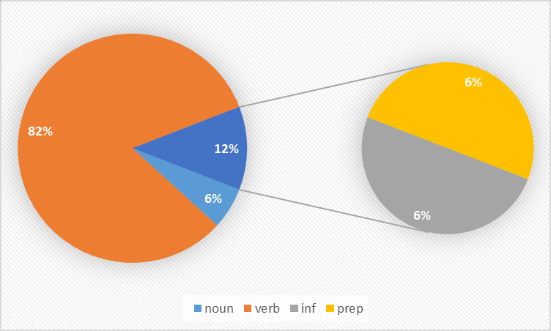
Figure 2. Word “love” POS possibility performance
Figures 1, 2, and 3 depict the POS possibility performance for the words luna, 'love,' and 'bee' respectively. These figures underscore the algorithm's excellence in noun detection, with probabilities favouring nouns over other POS categories, demonstrating its sensitivity and high accuracy in this regard. However, verb detection, as evidenced in Figure 2, proves to be comparatively more challenging. This revision provides a comprehensive overview of the Viterbi algorithm's functioning and its performance in POS tagging.
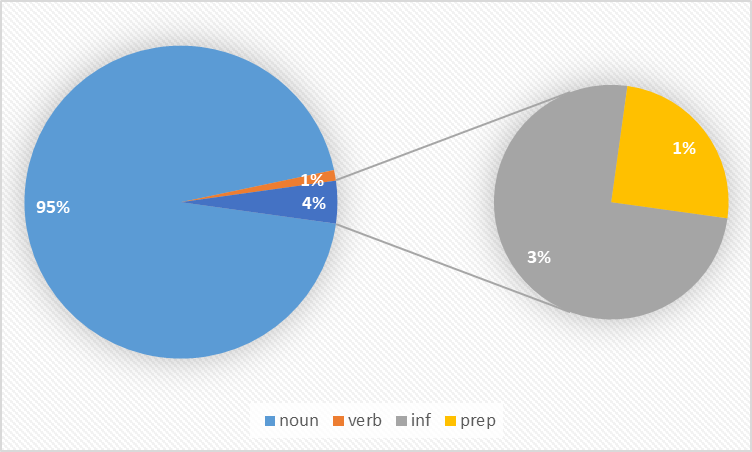
Figure 3. Word “bee” POS possibility performance
4. Conclusion
Part-of-Speech (POS) tagging stands as a valuable pre-processing technique, finding significance in applications such as text-to-speech synthesis, syntactic analysis, and machine translation. It facilitates human understanding by assigning grammatical tags to words. However, as the word count grows into the millions, manual tagging becomes infeasible, necessitating automated solutions.
The Viterbi algorithm, a dynamic programming approach, emerges as a solution for automated POS tagging. It recognizes that a word's POS is intricately tied to its position within a sentence and its neighbouring words. Employing dynamic programming, it computes word probabilities across various POS categories, selecting the most probable as the final POS tag.
Simulation results highlight the algorithm's proficiency in noun detection. Figures delineate the performance of words in four distinct POS categories, offering detailed insights into the Viterbi Algorithm's sentence detection capabilities.
Thus, when we receive bit information and transfer it to words, we can utilize Viterbi algorithm to help us understand word meaning. It can make bit error rate impact more smaller and let people understand transferred information much more accurately.