


1. Introduction
The first thing to introduce is the background of this research. My entire research was based on φ-OTDR, which is an optical time domain reflectometer, and φ-OTDR is a phase-based optical time domain reflectometer, which is a distributed sensor. He has many advantages: First, it can be continuously sensed in a large space range. Secondly, because its sensing and light transmission are the same optical fiber, the sensing part of the structure is simple and easy to use. Then, compared with the point sensor, the cost of information acquisition per unit length is reduced and the cost performance is high. As a sensing unit, optical fibers composite distributed fiber optic sensors and are capable of measuring millions of points. In the few past years, fiber optic acoustic sensing technologies have gone from quasi-distributed fiber sensing to distributed fiber sensing technologies, namely fiber Bragg grating, Michelson interferometers, Fabry-Perot interferometers, and φ-OTDR, each with its advantages, including cost, complexity, and performance. However, since φ-OTDR enables distributed monitoring of long distances in a relatively efficient manner, φ-OTDR has become the most widely used sensing technology in a few years. In addition, φ-OTDR systems have received more attention because of high dynamic range, the high sensitivity, full distribution, and relative simplicity of processing solutions compared to other fiber optic sensors. In recent years, researchers have significantly increased their interest in φ-OTDR systems, applying varies data processing methods to make effective event recognition and classification of φ-OTDR systems.
In [1], the authors acknowledge that detection on φ-OTDR systems is seriously influenced by fading noise, and even prior art such as signal averaging and differentiation may not be sufficient to detect high-frequency events. Shao et al. [2] argue that many φ-OTDR systems are seriously influenced by low signal-to-noise ratio (SNR), and that improving SNR is critical to improve the accuracy of identifying and locating external intrusions.
Here come the values of the research. Recently, the φ-OTDR system has made great strides in a few application areas, including perimeter safety monitoring, seismic wave prediction, airport derailment monitoring for aircraft take-off and landing, replacement of commonly used radar systems, oil and gas pipeline safety integrity, and underground tunnel monitoring. Submarine power cables, engineering structures, railways, bridges, underwater seismic signals, etc. Tu, G. , et al revealed a highly sensitive φ-OTDR system with a φ-OTDR system of more than 131.5 km in length that could be used for military bases and national border security on account of its high sensitivity and low NARs[3]. φ-OTDR systems are cost-effective systems, considering the length of the monitoring, and φ-OTDR systems can be integrated for detecting cracks in civil structures, or health monitoring of buildings [4]. What’s more, engine anomaly detection for disaster prevention, rail safety monitoring, oil and gas pipeline chemical leak monitoring, perimeter security intrusion detection are also suitable. In addition to so many advantages, φ-OTDR systems are simple to deploy, and φ-OTDR systems offer higher position accuracy and multi-point vibration detection compared to similar systems
We have introduced φ-OTDR, how important φ-OTDR systems are, and the challenges φ-OTDR systems are confronted with. Next, the paper is going to introduce my ways of research, the result of my research and the references mentioned in this work.
2. φ-OTDR working principle
The working principle of Ф-OTDR technology is that when the external disturbance action is used for sensing the optical fiber, the refractive index of the sensing fiber will be changed [5,6], so that the Rayleigh scattered light will produce phase modulation, and the intensity or phase information of the backward Rayleigh scattered light pulse signal in the fiber can be distributed sensing. After the coherent pulsed light is injected into the sensing fiber through the circulator, the generated backward Rayleigh scattered light is returned to the front end of the fiber, and is received by the photodetector through the circulator, and the external strain change information is restored by demodulation by the demodulation unit [7]. Intensity demodulation OTDR technology directly uses photodetectors for intensity detection for positioning external strains; Phase demodulation type φ-OTDR/DAS technology uses interferometer demodulation or coherent demodulation method, because the external strain change is proportional to the interference signal phase, the method can quantitatively restore the size, frequency and phase of the external strain change [8].
3. Lenet working principle
LeNet is the pioneering work of convolutional neural networks and a milestone in propelling deep learning to prosperity.
Yann LeCun proposed LeNet in the 1990s [9], and for the first time he used two new neural network components: convolutional layer and pooling layer; LeNet achieves impressive accuracy in handwritten character recognition tasks [10].
The LeNet network has a series of versions, of which the LeNet-5 version is the most famous and the best version in the LeNet series.
LeNet-5 uses 5 convolutional layers to learn image features [11]; The weight sharing feature of the convolutional layer makes it save a considerable amount of computation and memory space compared to the fully connected layer; At the same time, the local connection characteristics of the convolutional layer can ensure the spatial relevance of the image.
Through the convolutional layer, the signal characteristics can be enhanced and the noise can be reduced; Therefore, its main role is to reduce image noise and extract important features of images. In addition, the convolutional layer can ensure the translation invariance of the image, and the convolution operation retains the spatial information of the image, and the position relationship of the image after convolution does not change.
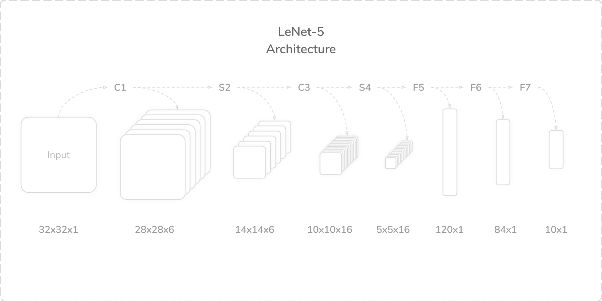
Figure 1. Structure diagram of LeNet-5.
The convolutional layer uses the convolutional kernel to convolute the image; Each convolutional kernel is trainable, and a bias parameter is typically added to the convolutional kernel. Convolution is a convolutional kernel moving on the original graph in steps, multiplying it with the convolutional kernel elements, and summing the multiplication result, and finally adding an offset to obtain the convolution result.
We call the result of the convolutional operation "Feature Map", and the size calculation formula of the feature map is as follows:
\( outpu{t_{size}}=\frac{inpu{t_{size}}-kerne{l_{size}}+2*padding}{stride}+1 \) (1)
Pooling operations are generally attached to the convolutional layer, and the main functions are:
(1) Reduce redundant information
(2) Expand the feeling field
(3) Prevent overfitting
(4) Improve the scale invariance, rotation invariance, and translational invariance of the model.
In this work, we use the activation function Relu, whose advantages are when x>0, the slope is always 1, so gradient dissipation problem is solved, and its convergence is fast. What’s more, it makes the network more sparsity. When x <0, the output of the layer is 0. The more neurons are 0 after training, the more sparsity it has, the better ability to generalization. It is obvious that getting the same effect, the fewer neurons that really work, the better generalization performance of the network has.
The shortcomings are if a gradient of the back layer is specifically large, causing the W to become specifically large after updating, causing the input < 0 of the layers and the output to be 0, then the layer will 'die' and it will be unable to update any more. Nearly half of the neurons die when the training starts if the learning rate is large, so it is of vital significance to set the learning rate reasonably.
The max (0, x) function has advantages as well as disadvantages that can either form the sparseness of the network or cause a lot of death of neurons and require tradeoff.
The fully connected layer is generally connected to the end of the convolutional neural network and is used to extract the feature vectors after convolution and pooling; Image classification is performed based on the extracted feature vectors. Therefore, the fully connected layer acts as both a feature extractor and a classifier.
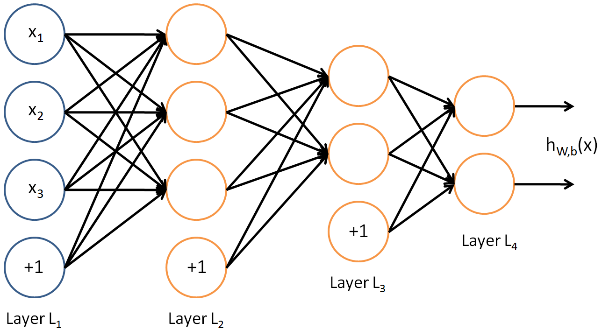
Figure 2. Structure diagram of neutral network.
Ordinary networks, like VGG, have no residuals, and experience will show that when network deepens, training errors will decrease at first and followed by an increase. Theoretically, the network will have better performance if it becomes deeper. But in fact, without residual model, the deeper the network is means the more difficult it is to train with optimization algorithms. As the depth of the network increases, the training error increases, which is described as network degradation. The proposal of the residual module can solve the above problems. Despite of a deeper network, the training performance is surprisingly well. It helps solve the problem of disappearing gradients and exploding gradients, allowing us to train deeper networks while guaranteeing good information. Experiments have shown that the residual block often requires more than two layers, and the residual block of a single layer (y = W 1 ∗ x + x) cannot work.
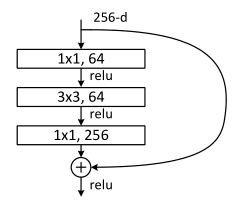
Figure 3. Process of neutral network.
4. Experiment and discussion
4.1. The dataset
The dataset is the data that the sensor transmits back to the computer when people perform different actions on the distributed sensor ϕ-OTDR. These events are background noise, digging, knocking, watering, shaking, and walking. Each event is saved with a .mat file and every event has 500 data files. The format of the file is a matrix of 10000*12, 10,000 sample points in the time domain of 0.8s, and 12 sample points in the air domain of 120m. The paper was to design a neural network that could classify and identify these actions more precisely.
4.2. Evaluation for deep learning methods in φ-OTDR
To evaluate the efficiency of the classifier, it is necessary to come up with a parameters to compare different models. In the paper, we use accuracy to analysis the efficiency of the model. Accuracy is the ratio of the data which is classified by the model correctly and the whole data. Its advantage is that the efficiency of the model can be evaluated easily and directly.
\( Accuracy=\frac{TP+TN}{TP+TN+FP+FN} \) (2)
TP means positive results detected correctly, the test result is correct and the result is positive. FP means positive results detected wrongly, the test result is wrong and the result is positive. TP means negative results detected correctly, the test result is correct and the result is negative. FN means negative results detected wrongly, the test result is wrong and the result is negative.
Table 1. Confusion matrix.
Predicted Class | |||
Actual Class | Population | Positive | Negative |
Positive | True Positive | False Negative | |
Negative | False Positive | True Negative | |
4.3. Comparison to classical classifiers
The original intention was was not ideal after reproducing after a lot of debugging. What I found was that the learning rate was too large after the code was applied to my dataset, and the number of trainings was too small, resulting in such a low accuracy rate. So I adjusted the learning rate to a smaller size, and after iteration, I improved the accuracy. Accuracy can be maintained stably above 86 percent. My overall idea is to simplify the recognition of the dataset matrix to image recognition. The first thing to do is to convert the two-dimensional matrix into a one-dimensional vector. This is the code section, Spread out the 10000*12 matrix with reshape. Next is the main part of the model. The size of the filter is 3*3, because my matrix is 10000*12, and the difference between length and width is large, so I set the step size to 5 and 1 so that the test will be better than the default parameters. Activate the function to use the return function. The matrix is then straightened with the flatten function and fed into the fully connected layer. Use the dropout function between layers to randomly throw away some elements to prevent overfitting. I found a lot of code on the Internet to reproduce, and the result is as follows.
All classifiers are the most accurate at identifying background noise, reaching more than 96%. Knocking and shaking are secondary, and the recognition accuracy can reach more than 80%. All classifiers have the worst classification effect on watering, and most classifiers have an accuracy of just over 70 percent. For background noise, KNN-SVML is the best at recognition, with an accuracy of more than 99%. For shaking events, NC-SVML recognition is the best, reaching 92.27%. For percussion and watering events, Adaboost.M1-KNN-SVML has the best recognition effect, reaching 93.57% and 86.72% respectively. On average, Adaboost.M1-KNN-SVML performed best overall, with an accuracy of 92.67% in event recognition.
Table 2. Comparison results.
Classifier | No Events | Shaking | Knocking | Watering | Average |
SVM | 98.35 | 85.90 | 86.96 | 75.65 | 86.71 |
KNN | 96.68 | 83.78 | 86.91 | 73.91 | 83.80 |
SVML | 97.96 | 89.91 | 92.83 | 77.94 | 89.66 |
NC-SVML | 98.53 | 92.27 | 90.86 | 79.42 | 90.27 |
KNN-SVML | 99.03 | 90.18 | 93.05 | 83.91 | 91.54 |
AdaBoost.M1-KNN | 98.23 | 88.83 | 89.20 | 78.29 | 88.63 |
AdaBoost.M1-KNN-SVML | 98.93 | 91.45 | 93.57 | 86.72 | 92.67 |
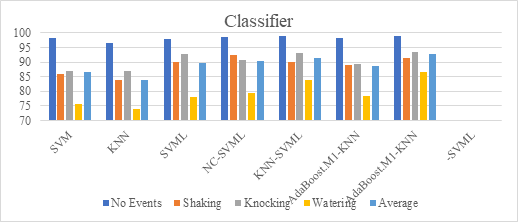
Figure 4. Results of different classifiers.
The model accuracy doesn't have any advantage over these classic classifiers. So I modified my improved model as a baseline to further improve the accuracy of the model. Because my baseline is based on lenet, I kept the convolutional layer plus pooling layer in it, introduced the residual module, and formed a resnet-like network structure. The difference between my model and resnet is that the convolutional layer and pooling layer of the resnet on the Internet do not fit my dataset well, so I fine-tuned the parameters such as step size, filter size, etc. on the basis of retaining the original convolutional pooling layer, and got the optimal solution. Second, the standard resnet network is too deep, for example, there will be 18 or 34 layers, etc., so I simplified some residual modules that are not very useful. Although the accuracy is not so perfect, the accuracy improvement compared to the previous lenet network is still very large, and it has exceeded the above classifier.
4.4. Result of the experiment
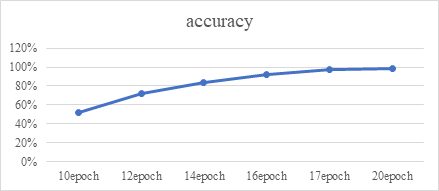
Figure 5. Accuracy of different epochs.
The dataset was divided to two parts, which is the training set and the test set. Training set takes 80% of the dataset and the test set takes 20%. After debugging, it is found that the convergence of the function can be achieved at the case of 17 epochs. The accuracy of this model can reach 97%. The accuracy rate that can be achieved by 10 epochs is 52%, and the accuracy that can be achieved by 16 epochs is 92%, and it is clear that the function has not yet fully converged. The accuracy rate of 20 epochs is about 98%, which is not much different from the accuracy rate of 17 epochs. Therefore, the introduction of the residual module can greatly improve the accuracy rate. It is obvious that this model is better than those classicial classifiers in terms of the accuracy.
5. Conclusion
In the paper, we have introduced ϕ-OTDR working principle firstly. And we expounded the meaning of researching the classification of it. As our main focus, how to increase the accuracy based on the conventional neural network Lenet, we introduced the residual module between the Convolutional layer and the Maxpooing layer in Lenet to increase the accuracy of the classifier. Also, the model uesd pretreatment and the accuracy increased a lot. The Lenet performs 86% in accuracy while after adding residual module in it the accuracy increased to 97%. It is obvious that the method is effictive in increasing the accuracy. The method can be widely used in daily life on account of its high accuracy.