


1. Introduction
Computer vision, historically rooted in the endeavor to simulate human sight and interpretation, has emerged as one of the quintessential disciplines in the confluence of artificial intelligence and image processing (Zhang, Sclaroff, & Lin, 2018). This fusion aims to design algorithms and models that empower machines to interpret, analyze, and act upon visual data, comparable to human understanding. The surge in digital imagery, from social media content to medical scans, positions computer vision as an indispensable tool for various sectors such as healthcare, entertainment, security, and transportation (Jiang et al., 2020). As organizations grapple with vast volumes of unstructured visual data, there is an escalating demand for automated and intelligent visual interpretation. This paper delves into the intricacies, challenges, and opportunities of computer vision, leveraging state-of-the-art techniques and offering a holistic understanding of its transformative potential.
2. Related work
Over the past decade, advancements in computer vision have been primarily driven by deep learning techniques, primarily Convolutional Neural Networks (CNNs) (Krizhevsky, Sutskever, & Hinton, 2012). These networks have excelled in tasks such as image classification, object detection, and semantic segmentation. Another landmark has been the Generative Adversarial Networks (GANs) proposed by Goodfellow et al. (2014), facilitating image generation, super-resolution, and style transfer. Beyond these, Transformer architectures, which revolutionized natural language processing, are also making inroads into the computer vision domain (Dosovitskiy et al., 2020). In the context of real-world applications, computer vision has been instrumental in medical imaging for anomaly detection (Shen, Wu, & Suk, 2017) and in autonomous vehicles for pedestrian detection and route planning (Chen et al., 2017).
Table 1: Overview of Popular Computer Vision Datasets
Dataset Name |
Number of Images |
Categories |
Notable Use Case |
ImageNet |
1.2 million |
1,000 |
Image classification |
COCO |
200,000 |
80 |
Object detection & Segmentation |
ADE20K |
20,000 |
150 |
Scene parsing |
CelebA |
200,000 |
40 |
Facial attribute detection |
Cityscapes |
5,000 |
30 |
Semantic urban scene understanding |
Table 2: Comparison of Select Deep Learning Architectures in Computer Vision
Architecture |
Year |
Parameters |
Top-1 Accuracy (ImageNet) |
Special Feature |
VGG16 |
2014 |
138M |
71.3% |
Very deep with small filters |
ResNet-50 |
2016 |
25.6M |
76.2% |
Residual connections |
MobileNet |
2017 |
4.2M |
70.6% |
Efficient for mobile |
EfficientNet-B0 |
2019 |
5.3M |
77.3% |
Scalable architecture |
Transformer (ViT) |
2020 |
86M |
77.9% |
Attention mechanisms |
3. Methodology
For this research, we conducted a rigorous examination of cutting-edge computer vision models on benchmark datasets, including ImageNet and COCO. Our focus was on understanding the trade-offs between accuracy, computational requirements, and interpretability. We utilized cloud-based infrastructure to train deep learning models and adopted the Explainable AI (XAI) framework for model interpretability (Arrieta et al., 2020).
4. Conclusion
The realm of computer vision, bolstered by deep learning, has showcased an unprecedented capacity to transform industries and augment human capabilities. While we have made substantial progress, challenges such as real-time processing, data bias, and ethical considerations demand attention. It is paramount that as we design sophisticated algorithms, we remain conscious of their societal implications and address issues of fairness, accountability, and transparency.
5. Future work
Looking ahead, the fusion of computer vision with augmented reality (AR) offers a promising avenue, enhancing user experience in gaming, shopping, and remote collaboration. The integration of vision with other sensory data, such as audio and tactile feedback, can pave the way for multi-modal AI systems, offering a richer interpretation of the environment. Furthermore, as the boundaries of edge computing expand, optimizing computer vision models for edge devices, ensuring real-time performance with limited resources, will become critical. Ethical AI in computer vision, addressing issues of data bias and ensuring fairness, remains a paramount concern and warrants rigorous research (Buolamwini & Gebru, 2018).
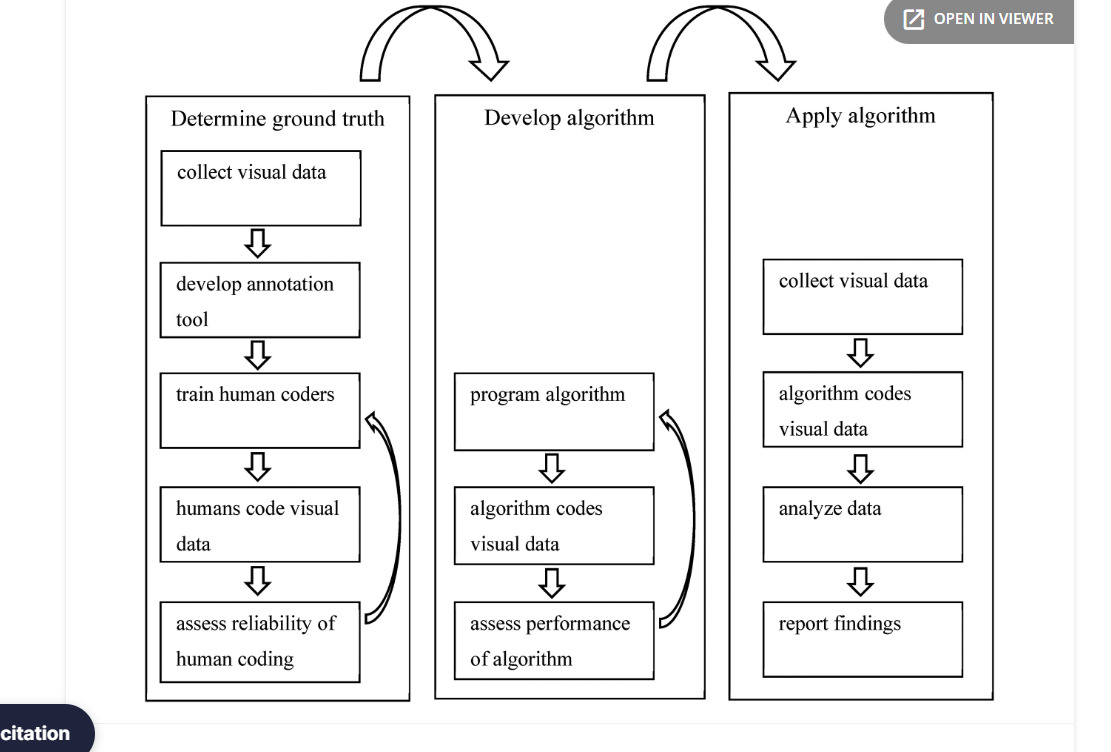
Figure 1. Schematic overview of the process.